


自然语言处理/文本处理

用于高速搜索大量双语语料库的工具
它可用于对文本数据进行降噪和搜索相似的句子和翻译。
无论目标双语语料库的字段如何,都可以使用它。
无论目标双语语料库的字段如何,都可以使用它。
用
该技术可用于从大量文本数据中提取相似的句子示例。
此外,我们还提供了用于构建行话词典的工具。
此外,我们还提供了用于构建行话词典的工具。
加工画面示例

流程示例 1
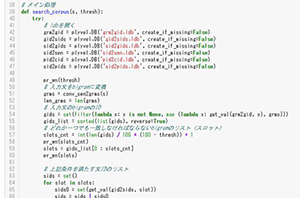
流程示例 2
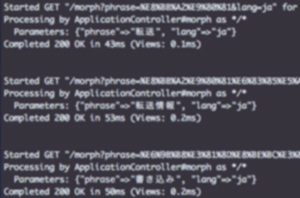
流程示例 3
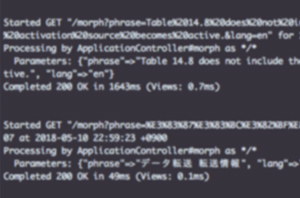
流程示例 4
输入文本和示例搜索结果
- 输入句子
- 我要坐飞机去上海。
- 搜索结果
- 他决定乘飞机去上海。 他决定坐飞机去上海.
- 下个月初,我将去上海。 下月初我要到上海去.
- 我经常坐飞机,但我不擅长。 我经常坐飞机,但我不喜欢飞机.
试用接受表
请填写下面的表格,让我们知道您想尝试什么。
您可以在视频中查看我们公司录制的作画面。
技术员寄语
除了通常的完全匹配和部分匹配搜索外,我们还创建了一个特殊的算法来搜索相似的句子。
此外,我们正在想方设法加快从数十万个句子中进行此类搜索的速度。
我认为这种机制可以应用于各种事情,例如字典示例、搜索、翻译记忆库等。
它在 Linux 上运行,可以在浏览器中访问。
此外,我们正在想方设法加快从数十万个句子中进行此类搜索的速度。
我认为这种机制可以应用于各种事情,例如字典示例、搜索、翻译记忆库等。
它在 Linux 上运行,可以在浏览器中访问。



