


文本处理简介:让我们在 Python 中快速制作字典(第 1 部分)

目录
[第 1 部分]
[第 2 部分]
[第 3 部分]
[第 4 部分]
文本处理的重要性
我叫 Kawakami,来自高电社开发办公室。
目前,使用神经网络的自然语言处理正在蓬勃发展。
Takadensha 还利用了传统基于规则的翻译 (RBMT) 和统计翻译 (SMT) 中培养的技术。
我们正在研究神经翻译 (NMT),这是神经网络的一项应用任务。
在自然语言处理领域,作为 warp 线程的一项重要技术是文本处理。
这次作为文本处理的介绍,对于对 Python 有一定了解的人来说,是字典程序
我们将向您展示如何制作它。 我们的目标是使实施尽可能简单实用。
本文中的示例程序在 jupyter-notebook 上使用 Python 3.6.x。
什么是字典查找(本文涵盖的内容)
字典查找程序的目的是将文本数据(例如,维基百科文章)转换为
所需的字符串 (headword; 例如,Wikipedia 是对标题字符串的搜索)。
为简单起见,让我们考虑对 headword 进行完全匹配搜索。
当您搜索文本数据并点击事先在字典中注册的一串标题词时
它显示预先注册的单词的含义。 有关此含义的更多信息,请参阅
数据库(尤其是非关系数据库,如键值存储)
拯救它是可以想象的。 我把这个留到下次再说,但这次
我们将只关注 “搜索” 的前半部分,并了解搜索索引的工作原理。
注意:如果您已经了解了大致的思路,并且只想阅读有关编程的知识,
请跳过下面的故事,从“双精度数组的 Python 实现 (1)”开始。
Trie Tree (TRIE) 的基本概念
当谈到搜索字符串匹配项时,首先想到的是关联数组。
Python 标准 dict 也是如此。 关于今年的主题,我还想记住一件事
Trie 是一棵树 (trie)。 它不包含在 Python 的标准库中,所以让我们制作它。
现在,让我们看一下下图中的 Trie 树示例。 “*” 是单词末尾的地标。
让我们数一数存储了多少个单词。
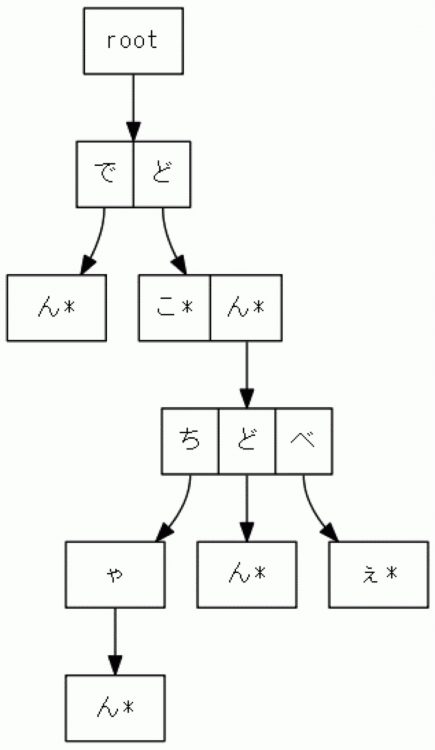
让我们从根转到 “*”。
有六个词:“den”、“where”、“don”、“don-chan”、“don-don”、“donbe”和“donbe”。
↓ 的尖端是子节点 (node),代表下一个字符,相邻的方格是
表示在同级节点中相同位置的字符选择。
严格来说,我们认为“一个节点通过字符数据过渡到下一个节点”,所以
字符数据写入箭头处。 (有关更多信息,请参阅学术书籍。
为了更容易实现,让我们把它做成一棵二叉树。
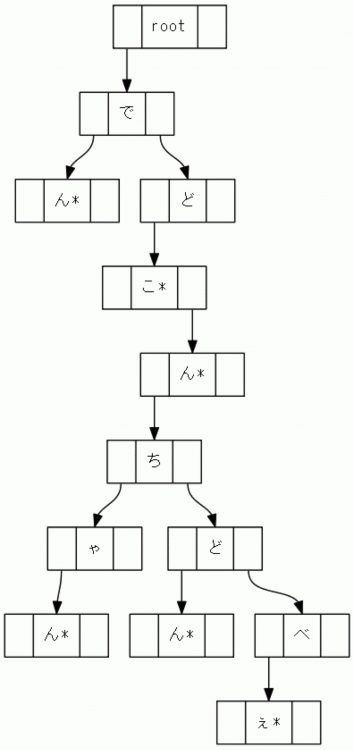
它比第一个数字更让人类感到困惑,但基本原理是相同的。 在此图的 Trie 树中,
左侧的 “↓” 的尖端是子节点,右侧的 “↓” 的尖端是同级节点。
标有 “*” 的节点称为叶节点。
这样,您可以通过从根节点到叶节点一个接一个地搜索字符来查找字典。
让我们考虑一下实现。 首先,为节点创建一个类。 作为会员:
左侧节点的索引号
右侧节点的索引号
- 节点的字符数据(或其字符代码)
・ 在叶节点的情况下,单词含义中的数据记录的编号(例如,当它不是叶节点时为 -1)
如果能有更多就好了。 接下来,我们将创建一个 Trie 树类。
首先,让我们将节点(上图中的 13 个)作为一个数组。
剩下的就是编写一个在 Trie 树中注册和搜索节点的方法 (?)。 )
即使采用如此简单的设计和实现,也可以进行高速搜索,并且可以用于自然语言处理的各种任务。
足够有用。 当我处理大量的文本数据时,我经常使用 Python 或 C++11。
我曾经编写和使用这样的 Trie 树程序。
关于 Double Array
现在,事情是这样的。 Trie 树有多种设计和实现。
目前主流的算法称为 double array。
它被提出已有 20 多年的历史,但理解的门槛有点高。
直到最近几年,我认为它一直被视为“专家喜欢的工具”。
现在,我可以阅读一个非常易于理解的解释,并且已经被咀嚼过了,所以我可以把它提供给公众(简单地说,
这是一项即使是像我这样理解正常的人也可以接触到的技术。
“信息科学硕士学位可以理解的双重安排”
http://d.hatena.ne.jp/takeda25/20120219/1329634865
在一篇易于理解的解释性文章中,也可以在网络上阅读,这是一个先驱。
“形态学分析的理论与实施”
https://www.amazon.co.jp/dp/4764905779
形态学分析的圣经。 第 4 章有几页,但有一个很好的解释。








